
Utiliser des données massives (big data) pour répondre à de grandes questions
21 octobre 2021

Dr. Nandita Basu est professeure et titulaire d’une chaire de recherche universitaire sur la viabilité globale de l’eau et l’écohydrologie à l’Université de Waterloo.
À titre de chercheuse hydrographique à l’université de Waterloo, Dr. Nandita Basu crée des modèles afin d’aider à répondre à de grandes questions. Dans quelle mesure les zones humides protègent-elles contre les proliférations d’algues? Où se trouvent les principaux points chauds du ruissellement agricole? Comment le changement climatique affecte-t-il la qualité de l’eau?
Cependant, ses modèles ne sont valables que dans la mesure où l’information qu’elle y alimente est bonne. « Ce qu’il y a de plus important lorsque l’on crée des modèles, ce sont les données, » dit Dr. Basu, qui détient la Chaire de recherche du Canada en viabilité globale de l’eau et écohydrologie.
Durant sa carrière universitaire aux États-Unis, Dr. Basu avait accès à un dépôt de données hydrographiques nationales provenant de plus de 400 agences locales, fédérales et d’états. Cependant, lorsqu’elle a déménagé en Ontario en 2013, son travail est devenu plus difficile.
Des données morcelées
Au lieu de se connecter à un portail unique, Dr. Basu et ses étudiants diplômés ont été contraints de rechercher des points de données dans un fouillis de sources. Parfois, les sites provinciaux contiennent les informations dont ils ont besoin. D’autres fois, ils doivent parcourir les rapports des offices de protection de la nature ou des municipalités. « C'est fastidieux », dit-elle.
Mais sécuriser les données n’est que la première étape. Ensuite, l’équipe doit d’abord nettoyer tout le « parasitage », en éliminant les valeurs aberrantes et en remédiant aux incohérences des données ; pour effectuer des comparaisons « d'une pomme avec une pomme », elle doit également s’assurer que les données provenant de différents ensembles sont exprimées de la même manière. Si une source exprime le nitrate en tant que nitrate, alors qu’une autre exprime le nitrate en tant qu’azote, par exemple, les chercheurs doivent effectuer des conversions. En outre, ils ont souvent affaire à des formats de fichiers différents.
Un autre défi consiste à relier différents points de données. Les niveaux de nutriments peuvent être testés à un endroit donné le long d’une rivière, mais les débits d’eau sont mesurés à un autre endroit ou à un autre moment, ce qui rend difficile l’obtention d’une image précise des charges de pollution.
Et cela, s'ils peuvent d’abord trouver l'information. Un bassin versant peut avoir des statistiques cohérentes d'une année sur l'autre, alors qu'une juridiction voisine présente de nombreuses lacunes. Certaines de ces lacunes peuvent être comblées par des calculs mathématiques. Mais plus les données sont rares, moins l’analyse est fiable.
Une meilleure façon de progresser
DataStream promet de faciliter la vie de Dr. Basu et ses collègues. À l’automne 2021, le lancement du plus récent carrefour régional, Great Lakes DataStream, permettra de rassembler des ensembles de données sur la qualité de l’eau dans l’ensemble des Grands Lacs et du bassin du Saint-Laurent dans un format normalisé. Et pour faciliter les comparaisons transfrontalières, ce format est aligné sur le référentiel de la qualité de l’eau des États-Unis. « L’harmonisation de ces différents ensembles de données est extrêmement précieuse », déclare Dr. Basu.
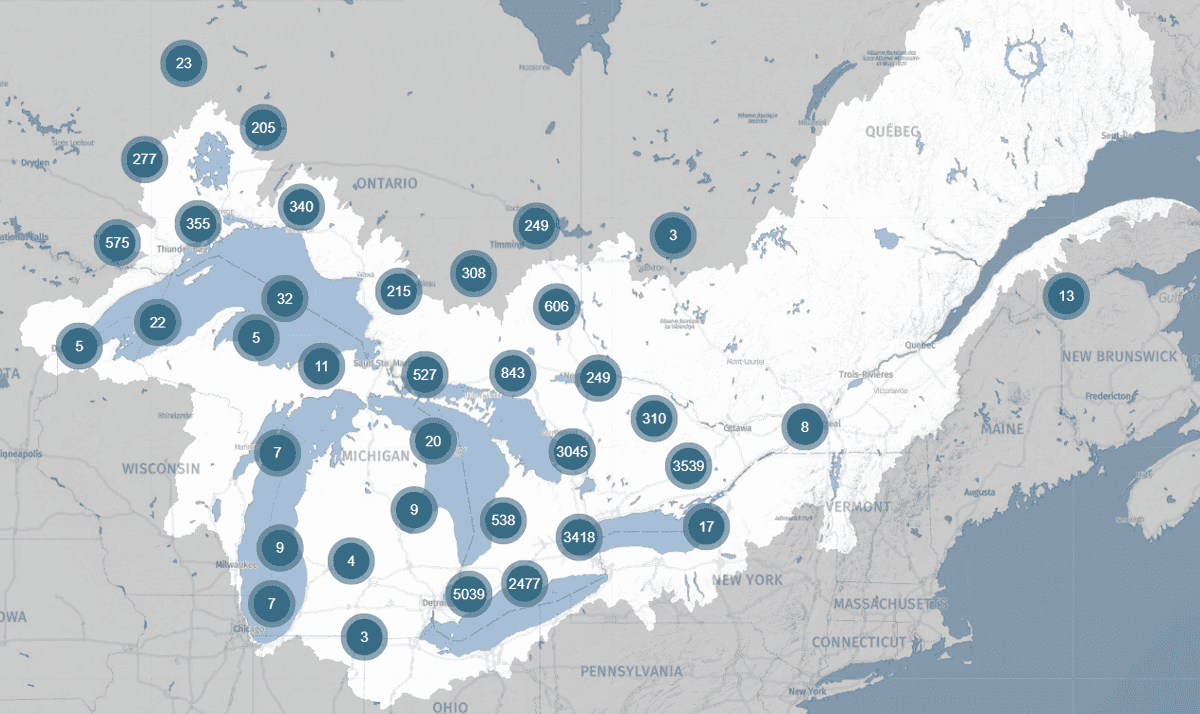
Great Lakes DataStream rassemble des données sur la qualité de l’eau collectées à travers le bassin des Grands Lacs et du Saint-Laurent.
En fin de compte, le nouveau carrefour DataStream aidera les chercheurs comme elle à trouver des solutions pour maintenir et améliorer la qualité de l’eau - des solutions qui pourraient aider une municipalité à décider de la taille de sa station d’épuration. Ou permettre aux agriculteurs de savoir quel est le meilleur moment pour appliquer des engrais. Ou encore à identifier les écosystèmes aquatiques qui ont besoin d’une protection accrue.
« Tant qu’il y aura de l’agriculture, tant qu’il y aura des gens, il y aura un excès de nutriments dans les cours d’eau », souligne le Dr. Basu. « Alors comment vivre de manière durable tout en protégeant l’environnement dans ce paysage? »
C’est une grande question, à laquelle elle espère que ses modèles contribueront à répondre - avec un peu de soutien de DataStream.

Cinq choses que vous ne savez peut-être pas sur le fleuve Mackenzie
Lors de la Journée mondiale des rivières, nous mettons en valeur le majestueux Mackenzie. Voici donc cinq faits pour vous aider à connaître le fleuve Mackenzie.

Les résultats sont disponibles ! Évaluation externe de DataStream pour 2023
Nous vous avons demandé vos commentaires, et vous avez répondu à l’appel ! À DataStream, nous sommes fiers de partager les résultats de notre évaluation externe de 2023.

Offre d’emploi: Directeur général / Directrice générale
Le directeur général / la directrice générale jouera un rôle essentiel dans la direction de DataStream en cette période de croissance stimulante.